

Your free pass to NVIDIA GTC, what LLM benchmarks measure, and a new GenAI platform launch
Your free pass to NVIDIA GTC, what LLM benchmarks measure, and a new GenAI platform launch
Plus the new direction of the newsletter and a life update from me!

What’s up, everyone?
I hope your 2024 has been off to an epic start. It’s been a busy and extremely learning-filled quarter for me, in the best ways. I’ve been on the grind and am ready to share everything I’ve learned. You’ll start hearing from me more consistently now.
Going forward, the newsletter will take on a new format.
Twice a month, you’ll get the roundup you’re used to (free events, news, blogs, cool GitHub repos, my two cents, and a distilled research paper). The other weeks will include some combination of technical deep dives, hands-on tutorials, random updates, and other things I’ve been thinking about or wanting to understand better myself. You can expect more hands-on coding content in the coming weeks as I flesh out content for my upcoming book on retrieval augmented generation and LinkedIn Courses (currently working on courses for RAG with LlamaIndex, text generation with Hugging Face, and fine-tuning LLMs with Hugging Face SFT and axolotl).
This week’s newsletter is brought to you by NVIDIA GTC!
Can’t make it to GTC but still want to attend virtually? I’ve got you covered; register to attend virtually here, and you can get into the virtual sessions for free!

Below are some sessions that I find most interesting, which NVIDIA has made open for you. First, you have to register for the virtual event. Then, you can add these to your schedule.
Customizing Foundation Large Language Models in Diverse Languages With NVIDIA NeMo
Rapid Application Development Using Large Language Models (LLMs)
Retrieval Augmented Generation: Overview of Design Systems, Data, and Customization
You can explore more Generative AI sessions here. Hundreds of virtual events are available, and I’m sure you will find something interesting and friendly for your time zone. There’s something for every persona that reads this newsletter: from students to data analysts, data scientists, researchers and beyond!
Note: Even if you don’t plan on attending any of the sessions, signing up using my link will help me tremendously.
How will it help me?
If my campaign has good results, I’ll secure at least one GPU from NVIDIA as part of their hardware exchange program. I’m GPU-poor and need them to research, so please…help me and sign up 🙏🏽😆.
Speaking of research, I’m launching an invite-only community for applied research.
This is a community where advanced practitioners can discuss nuanced topics, hack on projects just because they seem fun to hack on, explore weird and interesting directions of research, break things so they can figure out how to put it back together, and do research that seems weird and invaluable just because they're interested.
But such a space demands more than just interest—it requires a certain calibre of the members. This space will be different because the people in it are different.
Not learners, beginners, or those content to watch from the sidelines. I seek the advanced, the active, and those whose hands are on the keyboards daily with these models. People who are shaping the future with every line of code.
If you’re interested, apply here!
📊 What Do these LLM Benchmarks Mean?
Evaluating LLMs is hard. For several reasons:
Difficulty assessing nuance, context, and reasoning
Variability and inconsistency in outputs
Lack of interpretability and explainability
Resource-intensive evaluation
Difficulty of evaluating open-ended generation
Overcoming these challenges is an active area of research involving developing better metrics, benchmarks, stress tests, human evaluation protocols, and transparency tools. However, evaluating LLMs remains fundamentally difficult due to their black-box nature and the open-ended nature of language generation.
Despite this, we still try because evaluating LLMs is important.
The way I see it, LLM evaluations can be divided into two categories:
Benchmarks
Vibe checks
Benchmarks gauge the LLMs overall performance on a dataset, while vibe checks are informal assessments performed manually by an AI engineer.
Vibe checks are subjective and difficult to compare across models, while benchmarks provide insights into the LLM's strengths, weaknesses, and performance compared to other models.
At least one pain in the ass about benchmarks is that…there are SO MANY benchmarks out there!
Some benchmarks evaluate the knowledge and capability of LLMs by rigorously assessing their strengths and limitations across a diverse range of tasks and datasets. Other benchmarks assess how well-aligned an LLM is - evaluating their ethics, bias, toxicity, and truthfulness. Some benchmarks evaluate the robustness of LLMs by measuring their stability when confronted with disruptions. There are risk evaluations that examine general-purpose LLMs behaviours and assess them as agents. There are even benchmarks for assessing an LLMs knowledge of domains as diverse as biology and medicine, education, legislation, computer science, and finance.
But, over the last year or so, the community has seemed to converge around what I call the “big six.”

These benchmarks, used to assess base LLMs, include ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K. You’ve seen them on the Hugging Face Open LLM Leaderboard, powered by Eluther AI’s Language Model Evaluation Harness.
But what are these benchmarks? What do they measure?
Each of these benchmarks uniquely assesses different aspects of LLMs, including reasoning, commonsense understanding, knowledge acquisition, truthfulness, logical deduction, and problem-solving abilities.
ARC (AI2 Reasoning Challenge)
Released in 2018 by the Allen Institute for AI
Contains 7,787 multiple-choice science questions for grades 3-9
Measures an LLMs ability to reason and apply scientific knowledge
Important because it tests higher-level reasoning and knowledge beyond just language understanding
Pros: Challenging questions that require reasoning.
Cons: Limited to multiple-choice format.
HellaSwag (Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations)
Released in 2019 by researchers from UW, AI2 and others
Contains 70,000 multiple-choice questions
Measures an AI system's ability to use commonsense reasoning to complete descriptions of situations
Pros: Focuses specifically on commonsense reasoning.
Cons: Contains some ambiguous or subjective questions.
MMLU (Massive Multitask Language Understanding)
Released in 2021 by researchers from Stanford, DeepMind, Google and others
Contains ~16,000 multiple-choice questions from 57 topics, including STEM, social science, humanities
Measures an LLMs multitask accuracy across a broad range of academic and professional subjects
Important because it comprehensively evaluates the breadth of knowledge
Pros: Very broad coverage of knowledge domains.
Cons: Answers can be answered via information retrieval vs. reasoning
TruthfulQA
Released in 2022 by researchers from UMass Amherst and Google
Contains 817 questions designed to probe truthfulness and the ability to avoid false or misleading answers
Measures an AI system's factual accuracy and calibration
Important because it evaluates truthfulness, which is critical for real-world applications
Pros: Focuses on truthful answering, an important capability.
Cons: Relatively small dataset.
Winogrande
Large-scale dataset of 43,985 Winograd Schema Challenge (WSC) problems
Introduced in 2020 to more rigorously evaluate machine commonsense reasoning
Adversarially constructed to be robust against statistical biases in existing WSC datasets
Highlights that models may be exploiting biases rather than achieving true commonsense understanding
GSM8K (Grade School Math)
Released in 2021 by researchers from UC Berkeley, Google and others
Contains 8,500 high-quality grade-school math word problems
Important because it evaluates mathematical reasoning, a key component of intelligence
Pros: High-quality problems that test mathematical reasoning.
Cons: Focused only on math word problems.
For chat and instruction-tuned models, we have the Holy Trinity of evals.

These are interesting because they’re evaluating models on open-ended generation…and evaluating the models in interesting ways!
One of these interesting ways is the LLM-as-a-Judge approach. This leverages LLMs as judges to evaluate chat assistants based on open-ended questions. MT-bench and Chatbot Arena benchmarks show that LLM judges like GPT-4 can match human preferences with over 80% agreement. LLM judges complement traditional benchmarks and offer a cost-effective way to evaluate chat assistants.
LMSys Chatbot Arena
Uses a pairwise comparison approach where users chat with two anonymous models side-by-side and vote for the better response
Has collected over 240K votes across 45 models as of March 2024
Computes an Elo rating for each model based on the pairwise votes to rank them on a leaderboard
Pros: Crowdsourced diverse questions, tests real-world open-ended use cases, ranks models by human preference
Cons: Votes may be noisy/biased, expensive to run
AlpacaEval/ AlpacaEval 2
AlpacaFarm is a dataset of 52,000 instructions and demonstrations
Compares model outputs to a reference model using an LLM-based annotator
Provides a leaderboard ranking model by win rate over the reference
Pros: Fast, cheap, reliable proxy for human eval on instruction-following
Cons: Biased towards verbose outputs, limited to simple instructions, not comprehensive
MT Bench (Multi-turn benchmark)
Contains 80 high-quality multi-turn questions across 8 categories
Evaluate instruction-following, knowledge, reasoning, etc. over multiple turns
Provides a score for each model and is used alongside Elo ratings in the Chatbot Arena leaderboard
Pros: Tests challenging multi-turn abilities, provides category breakdowns, uses strong LLM judge
Cons: GPT-4 judge can make errors, especially on math/reasoning, limited to 80 questions
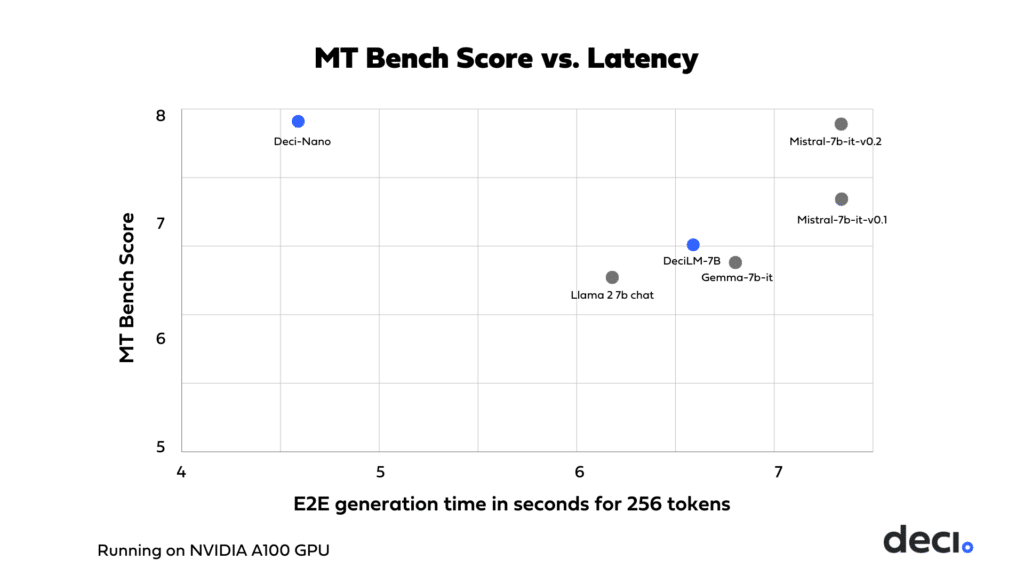
Deci AI launches a new model and Generative AI platform!
You can read more about the model and the platform here. It has amazing scores across all benchmarks and is blazingly fast! You can try it for yourself in the playground here.
Signing up for the API is free; no credit card is required.
Enjoy!
More of a code-first type of person? Me, too!
Here’s a tutorial notebook which will walk you through using the API via cURL, requests, and the OpenAI SDK.
Here’s a tutorial notebook showing how to use it in LangChain.
And finally, a notebook showing you how to use the API along with LangChain and LangSmith
Happy hacking!
Life update: I’m now at Voxel 51!

I’ve joined Voxel 51 as a Hacker-in-residence!
A what?
Hacker. In. Residence.
You can think of it as a DevRel role but in its purest form (i.e., none of that marketing/SEO “content creation” bullshit).
I’ll tinker with new technologies, hack around with the latest foundation models, and take what I learn and bring it back to you! I’ll explore my curiosity with vision-language and multimodal models, explore applications of the fiftyone library for RAG workflows, use the open-source fiftyone library in interesting ways(for data curation, model debugging, and data-centric AI workflows), and contribute to open-source AI!
I’m excited about this role, what I can bring to the team, the awesome stuff I can do with the team, and what the future holds for the company!
Note: While I am full-time at Voxel 51, my main gig, I’ve agreed to stay at Deci in a fractional capacity on a contract basis. I’ll continue to red-team and vibe-check their LLMs while helping them find and recruit my replacement. If you’re in DevRel, have been considering a career in DevRel, or know your way around LLMs, send me a message with your resume and somewhere I can scope your work (GitHub, Medium, YouTube, personal blog, etc)!
That’s it for this one!
Cheers, and see you around!
Just signed up for my free virtual pass to NVIDIA GTC - thanks, Harp!
Really informative and helpful.