


The NeurIPS Preview Edition
Research deep-dives & expert interviews + announcing my hands-on GenAI course for practitioners

I'm heading to NeurIPS 2024 in Vancouver and couldn't be more excited.
After attending CVPR, ECCV, and ICCV over the years, NeurIPS has always been the one conference I really wanted to experience. I've spent the last month reading through accepted papers and talking with researchers about their work, and the quality of research this year is incredible. Before I jump on that plane to Vancouver, I wanted to share some of the most interesting conversations and papers I've come across.
Consider this newsletter your insider's preview of what's coming at NeurIPS 2024.

🤔 What's in this edition
🎯 NeurIPS 2024 Preview
Deep dives into groundbreaking papers and conversations with researchers
🔍 Research Spotlight
Zero-shot learning: Are we measuring what we think?
SPIQA: Revolutionizing scientific paper understanding
KnoBo: A new approach to medical imaging
NaturalBench: Better VLM evaluation
Dataset distillation breakthroughs
Building better vision-language models
📊 Data-Centric AI Focus
Five must-read papers challenging how we think about data quality and curation
Real vs. Synthetic: Why retrieved images outperform synthetic data
SELFCLEAN: A new approach to data quality audits
SELECT: Benchmarking data curation strategies
ConBias: Tackling concept bias in visual datasets
Understanding bias in large-scale visual datasets
Btw, If you found the newsletter helpful, please do me a favour and smash that like button!
You can also help by sharing this with your network (whether via re-stack, tweet, or LinkedIn post) so they can benefit from it, too.
🤗 This small gesture and your support mean far more to me than you can imagine!
I’m launching a course: Applied Generative AI for Data Professions

Many of you have reached out asking for ways to learn more about Generative AI and how to apply it effectively.
After months of preparation, I'm excited to announce my new course: Applied Generative AI for Data Professionals.
This comprehensive course combines theory and hands-on practice, covering:
Working with LLMs and Vision Language Models
Essential tools like LangChain, LlamaIndex, and frameworks for observability
Practical patterns including Prompt Engineering, RAG, Agents, and Fine-tuning
Building evaluation frameworks to ensure quality outputs
If you’ve been following me for a while, you know my courses are hands-on and technical. You’ll walk away from this course with an intuition for how these models work, plus hands-on experience interacting with them.
What makes this course unique is that it’s all killer, no filler:
14 interactive live sessions
Direct access to me as your instructor
Hands-on projects with guided feedback
A private community of peers
Lifetime access to materials
I work with these technologies daily and stay current with the latest research. My teaching approach focuses on building intuition while keeping math accessible.
Limited Time Offer: Use code COHORTONE for 50% off
This brings the course cost to $249 - which I think is a great value for what we’ll cover together.
You can learn more about the course, check out the syllabus, and sign up for it here!
I'd also appreciate your input on how to help shape the course content. Please take a few minutes to fill out this brief survey.
Looking forward to helping you build practical GenAI skills!
The NeurIPS Preshow!
In preparation for NeurIPS 2024, I had the privilege of sitting down with several brilliant researchers to discuss their accepted papers, each addressing critical challenges in AI development and evaluation.
From questioning the fundamentals of zero-shot learning to revolutionizing scientific paper comprehension and medical image analysis, these conversations reveal the critical thinking and innovation at the forefront of machine learning research.
NaturalBench: Evaluating Vision-Language Models
In conversation with Zhiqiu Lin, we explored how current benchmarks may overestimate the capabilities of Vision-Language Models (VLMs). Their work introduces NaturalBench, a new evaluation framework that reveals significant gaps between perceived and actual model performance by forcing VLMs to rely on visual understanding rather than language shortcuts.
Here’s a link to our chat and summary of the work.
Dataset Distillation Through Soft Labels
Sunny Qin's research challenges conventional wisdom in dataset compression, demonstrating that probabilistic "soft" labels are more valuable than synthetic image generation. Her work shows how expert-generated soft labels can achieve comparable performance to leading distillation methods while using significantly less data.
Here’s a link to our chat and summary of the work.
Building Better Vision-Language Models
Hugo Laurençon shared insights from developing Idefics2, exploring the critical architectural decisions and training strategies in VLM development. His research reveals the advantages of self-attention architectures and the importance of synthetic captions in training data, while addressing the challenges of maintaining model efficiency and ethical considerations.
Here’s a link to our chat and summary of the work.
Zero-Shot Learning: A Misnomer?
Vishaal Udandarao's research challenges the conventional wisdom around zero-shot learning, revealing that what we consider "zero-shot" capabilities may actually be recognition of concepts already present in training data. His team's analysis of 34 multimodal models demonstrates that concept frequency in pre-training data strongly predicts performance, suggesting we need exponential data increases for linear improvements in model capabilities.
Here’s a link to our chat and summary of the work.
SPIQA: Revolutionizing Scientific Paper Understanding
Shraman Pramanick introduces SPIQA, a groundbreaking dataset addressing the limitations of AI systems in comprehending scientific papers. By incorporating visual elements from 26,000 computer science papers, including 150,000 figures and 117,000 tables, SPIQA enables AI systems to better understand the crucial interplay between text and visuals in scientific literature.
Here’s a link to our chat and summary of the work.
KnoBo: A New Approach to Medical Image Analysis
Yue Yang presents Knowledge Enhanced Bottlenecks (KnoBo), an innovative solution to domain shifts in medical image analysis. By incorporating explicit medical knowledge from textbooks and research papers, KnoBo creates more robust and interpretable AI models that better mirror how medical professionals learn and make decisions.
Here’s a link to our chat and summary of the work.
Five Must Read Data-Centric AI Papers from NeurIPS 2024
Despite practitioners universally acknowledging that data quality is the cornerstone of reliable AI systems, only 56 out of 4,543 papers at NeurIPS 2024 explicitly focused on data-centric AI approaches.
While this represents a doubling from 2023’s 28 papers, it remains a surprisingly small fraction given data’s outsized role in real-world AI success. Ask any machine learning engineer about their biggest challenges, and you’ll likely hear about data quality issues, bias in training sets, or the endless hours spent cleaning and curating datasets. Yet, the academic focus remains heavily skewed toward model architectures and optimization techniques.
This disconnect between practical reality and research emphasis makes the data-centric AI papers at NeurIPS 2024 particularly valuable.
In this series of blog posts, I’ll explore this select but crucial body of work tackling the foundation of AI development — the data itself. From new methodologies for auditing data quality to frameworks for understanding dataset bias, these papers offer critical insights for bridging the gap between academic research and practical implementation. I’ll examine current research about approaches to data curation, challenge assumptions about synthetic data, and investigate the potential of dynamic “foundation distributions” that adapt during training.
For anyone building or deploying AI systems, these findings could be more immediately impactful than the latest architectural innovation. After all, as the old programming adage goes: garbage in, garbage out — no matter how sophisticated your model, because data eats models for lunch.
The five papers covered in this series:
The Unmet Promise of Synthetic Training Images: Using Retrieved Real Images Performs Better
SELECT: A Large-Scale Benchmark of Data Curation Strategies for Image Classification
Below are brief overviews of the papers, each followed by a link to my full breakdown.
The Unmet Promise of Synthetic Training Images: Using Retrieved Real Images Performs Better
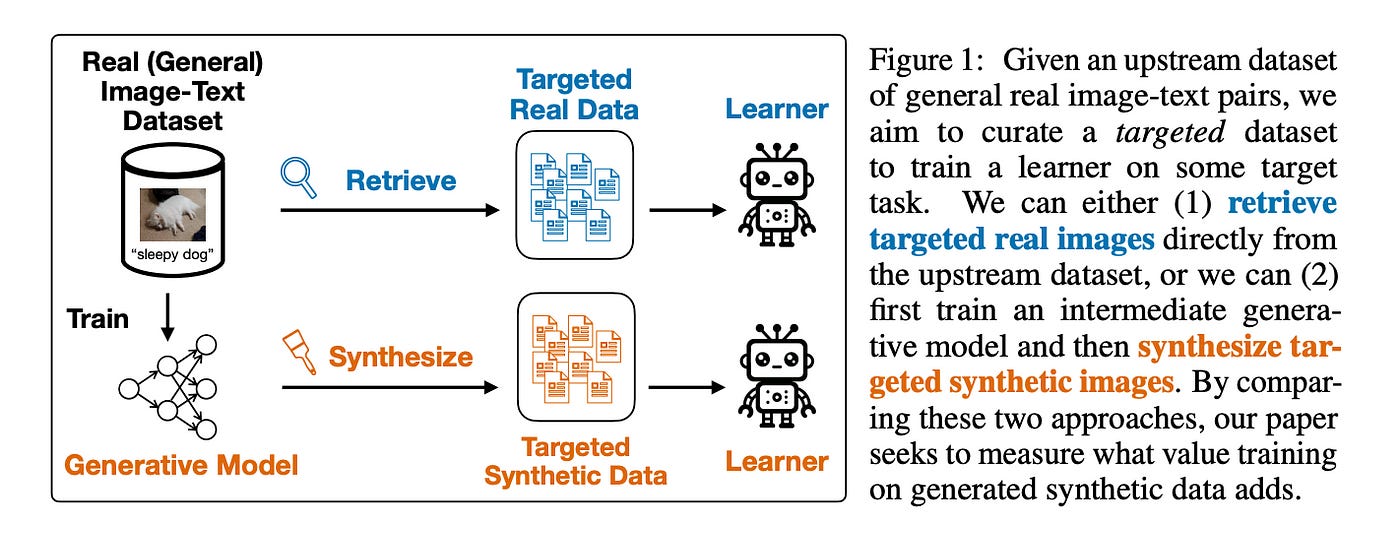
This work investigates the efficacy of using synthetic data generated by text-to-image models for adapting pre-trained vision models to downstream tasks.
Specifically, the authors compare the performance of models fine-tuned on targeted synthetic images generated by Stable Diffusion against models fine-tuned on targeted real images retrieved from Stable Diffusion’s training dataset, LAION-2B. The authors conduct experiments on five downstream tasks: ImageNet, Describable Textures (DTD), FGVC-Aircraft, Stanford Cars, and Oxford Flowers-102, and evaluate model performance using zero-shot and linear probing accuracy. Across all benchmarks and data scales, the authors find that training on real data retrieved from the generator’s upstream dataset consistently outperforms or matches training on synthetic data from the generator, highlighting the limitations of synthetic data compared to real data. The authors attribute this underperformance to generator artifacts and inaccuracies in semantic visual details within the synthetic images.
Overall, the work emphasizes the importance of considering retrieval from a generative model’s training data as a strong baseline when evaluating the value of synthetic training data.
You can read a full breakdown of this work here.
Intrinsic Self-Supervision for Data Quality Audits

This work presents SELFCLEAN, a data cleaning procedure that leverages self-supervised representation learning to detect data quality issues in image datasets.
SELFCLEAN identifies off-topic samples, near duplicates, and label errors using dataset-specific representations and distance-based indicators. The authors demonstrate that SELFCLEAN outperforms competing methods for synthetic data quality issues and aligns well with metadata and expert verification in natural settings. Applying SELFCLEAN to well-known image benchmark datasets, the authors estimated the prevalence of various data quality issues and highlighted their impact on model scores.
Their analysis emphasizes the importance of data cleaning for improving the reliability of benchmark performance and boosting confidence in AI applications.
You can read my full breakdown of this paper and my takeaways here.
SELECT: A Large-Scale Benchmark of Data Curation Strategies for Image Classification
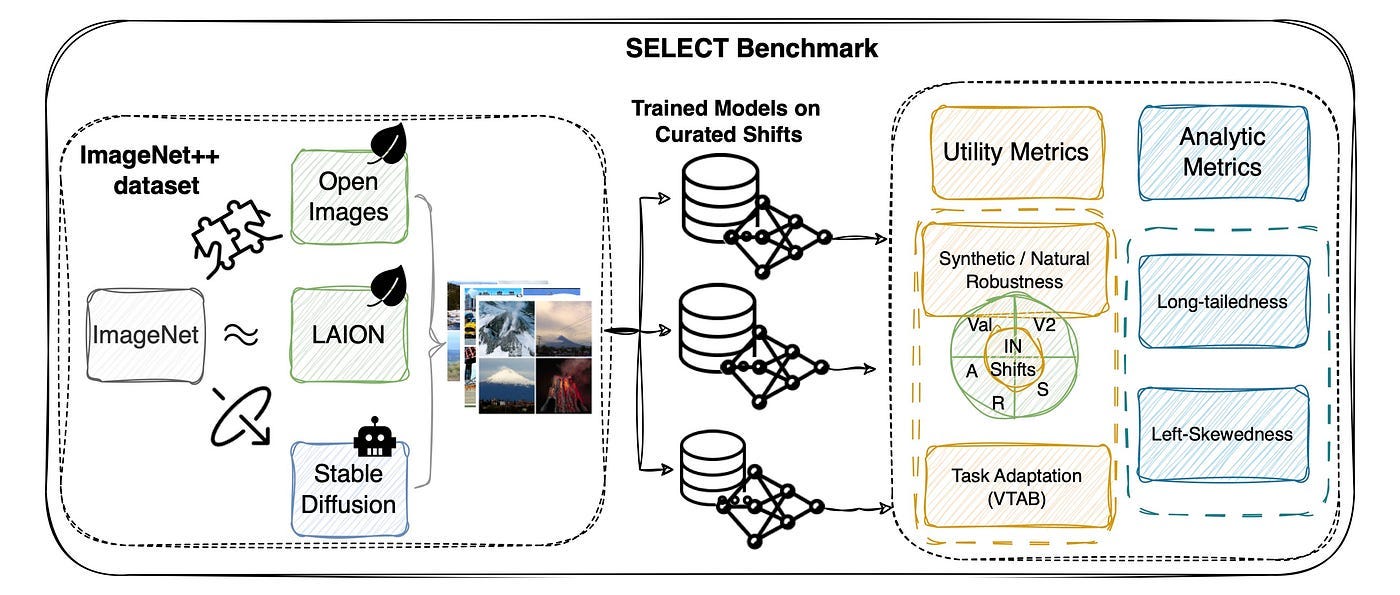
This work introduces SELECT, a benchmark for evaluating data curation strategies for image classification, and IMAGENET++, a dataset used to generate baseline curation methods.
The authors created IMAGENET++ by extending ImageNet with five new training-data shifts; each assembled using a distinct curation strategy including crowdsourced labeling, embedding-based search, and synthetic image generation. The authors evaluated these data curation baselines by training image classification models from scratch and inspecting a fixed pretrained self-supervised representation. Their findings indicate that while reduced-cost curation methods are becoming more competitive, expert labeling, as used in the original ImageNet dataset, remains the most effective strategy.
The authors suggest that future research focus on improving cost-effective data filtration, sample labeling, and synthetic data generation to further bridge the gap between reduced-cost and expert curation methods.
You can read a full breakdown of the paper and my key takeaways here.
Visual Data Diagnosis and Debiasing with Concept Graphs

This paper introduces ConBias, a novel framework for diagnosing and mitigating concept co-occurrence biases in visual datasets.
ConBias represents visual datasets as knowledge graphs of concepts, which enables the analysis of spurious concept co-occurrences to identify concept imbalances across the dataset. This approach targets object co-occurrence bias, which refers to any spurious correlation between a label and an object causally unrelated to the label. Once concept imbalances have been identified, CONBIAS generates images to address under-represented class-concept combinations, leading to a more uniform concept distribution across classes. This process involves prompting a text-to-image generative model to create images of under-represented concept combinations.
Extensive experiments show that data augmentation based on a balanced concept distribution generated by ConBias enhances generalization performance across multiple datasets, outperforming state-of-the-art methods.
Check out the blog for a full breakdown of ConBias.
Understanding Bias in Large-Scale Visual Datasets

This paper uses three popular datasets (YFCC, CC, and DataComp) as a case study to explore the different forms of bias in large-scale visual datasets.
The authors develop a framework based on applying various image transformations to isolate specific visual attributes (e.g., semantics, structure, color, frequency) and then assess how well a neural network can still classify the images based on their original dataset after these transformations. Strong classification performance after a transformation suggests that the targeted attribute contributes to dataset bias. The study reveals that these datasets exhibit significant biases across all the examined visual attributes, including object-level imbalances, differences in color statistics, variations in object shape and spatial geometry, and distinct thematic focuses.
The authors emphasize that understanding these biases is essential for developing more diverse datasets and building robust, generalizable vision models.
Thanks for reading!
If you found the newsletter helpful, please do me a favour and smash that like button!
You can also help by sharing this with your network (whether via re-stack, tweet, or LinkedIn post) so they can benefit from it, too.
🤗 This small gesture and your support mean far more to me than you can imagine!
Cheers,
Harpreet